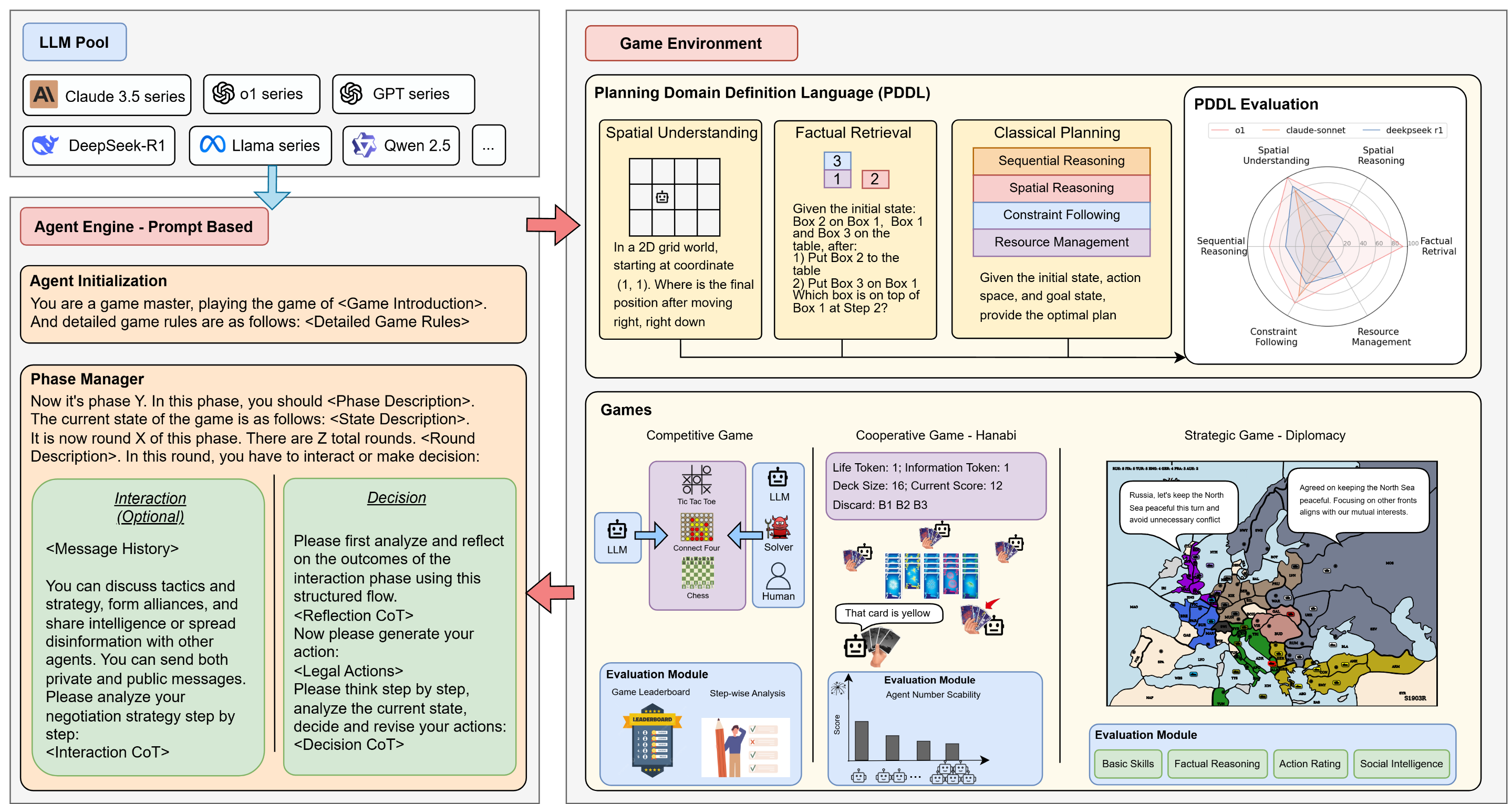
We introduce Strategic Planning, Interaction, and Negotiation (SPIN-Bench), a comprehensive framework
for evaluating
long-horizon strategic planning and social intelligence in Large Language Models (LLMs).
Unlike prior work that confines itself to narrow planning or isolated single-agent tasks,
SPIN-Bench combines formal PDDL challenges, competitive board games, cooperative card games,
and multi-agent negotiation scenarios within a single evaluation.
By systematically varying action spaces, state complexity, and the number of interacting agents,
SPIN-Bench tests not only methodical, step-wise decision-making but also
conceptual inference about hidden information and adversarial or cooperative strategies.
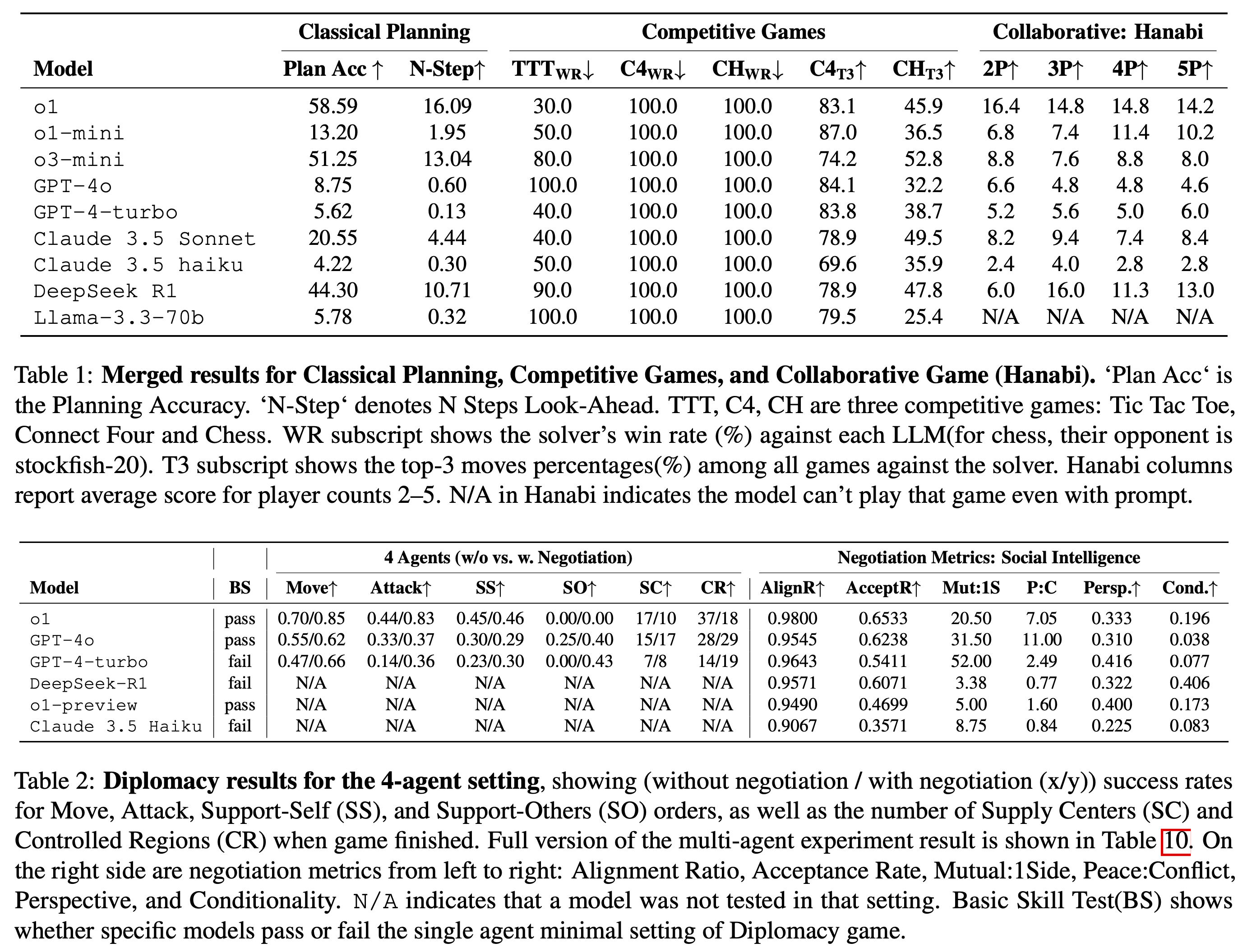
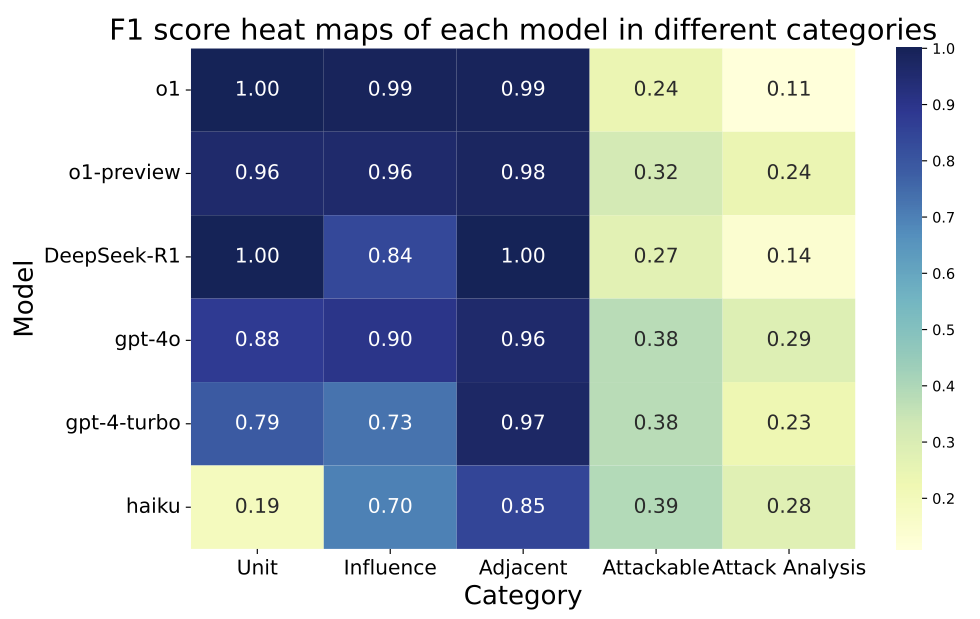
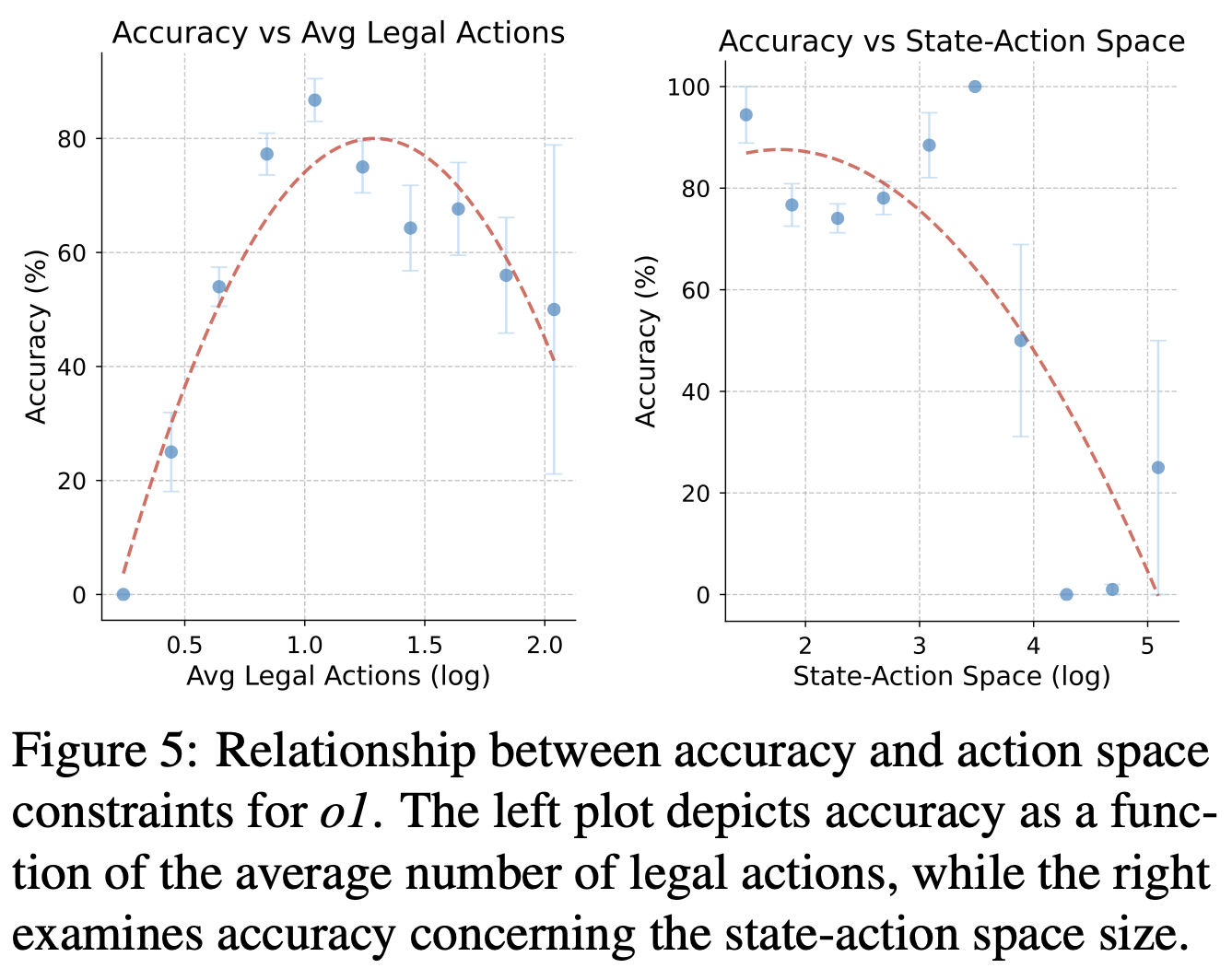
Our experiments reveal that while contemporary LLMs handle basic fact retrieval and
short-range planning reasonably well, they encounter significant performance bottlenecks
in tasks requiring deep multi-hop reasoning over large state spaces and socially adept
coordination under uncertainty.
In particular, we find that strong models (e.g., o1) can still struggle with
extended-horizon planning when multiple agents and hidden intentions are introduced,
and that extensive social interaction can sometimes degrade chain-of-thought coherence.
These insights highlight persistent gaps in multi-agent negotiation,
alliance formation, and perspective-taking, underscoring where further
advances in LLM architectures and training might be needed.
By drawing on both human baselines and domain-specific solvers, our results shed light on the
real-world potential and current shortcomings of LLMs for strategic, multi-agent settings.
We envision SPIN-Bench as a catalyst for future research on robust multi-agent planning,
social reasoning, and human–AI teaming.
The SPIN-Bench framework integrates four distinct environment types:
- PDDL Tasks: Classical planning problems across 21 domains (1,280 tasks) spanning factual retrieval,
spatial reasoning, and multi-step planning with increasing state spaces.
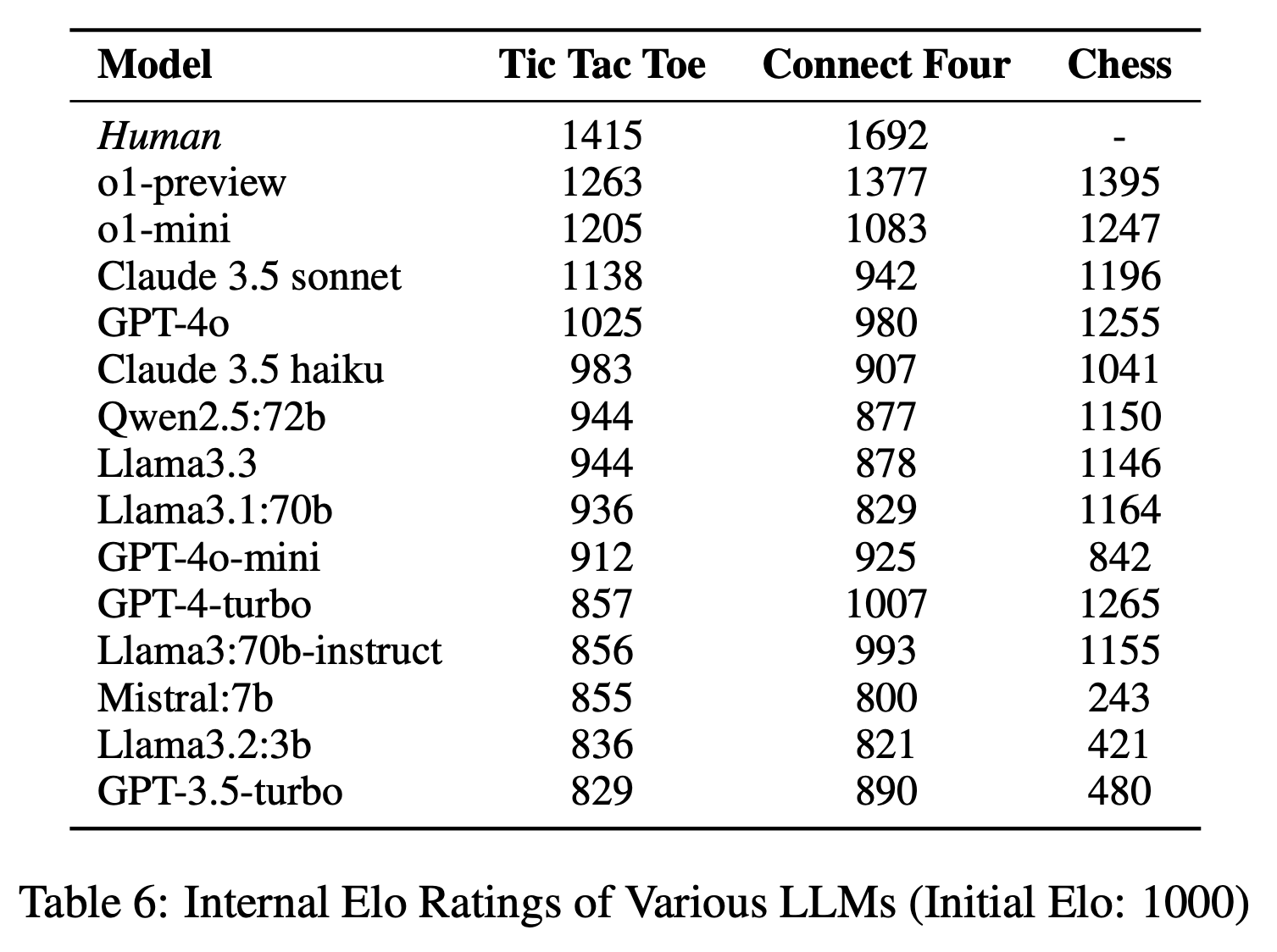
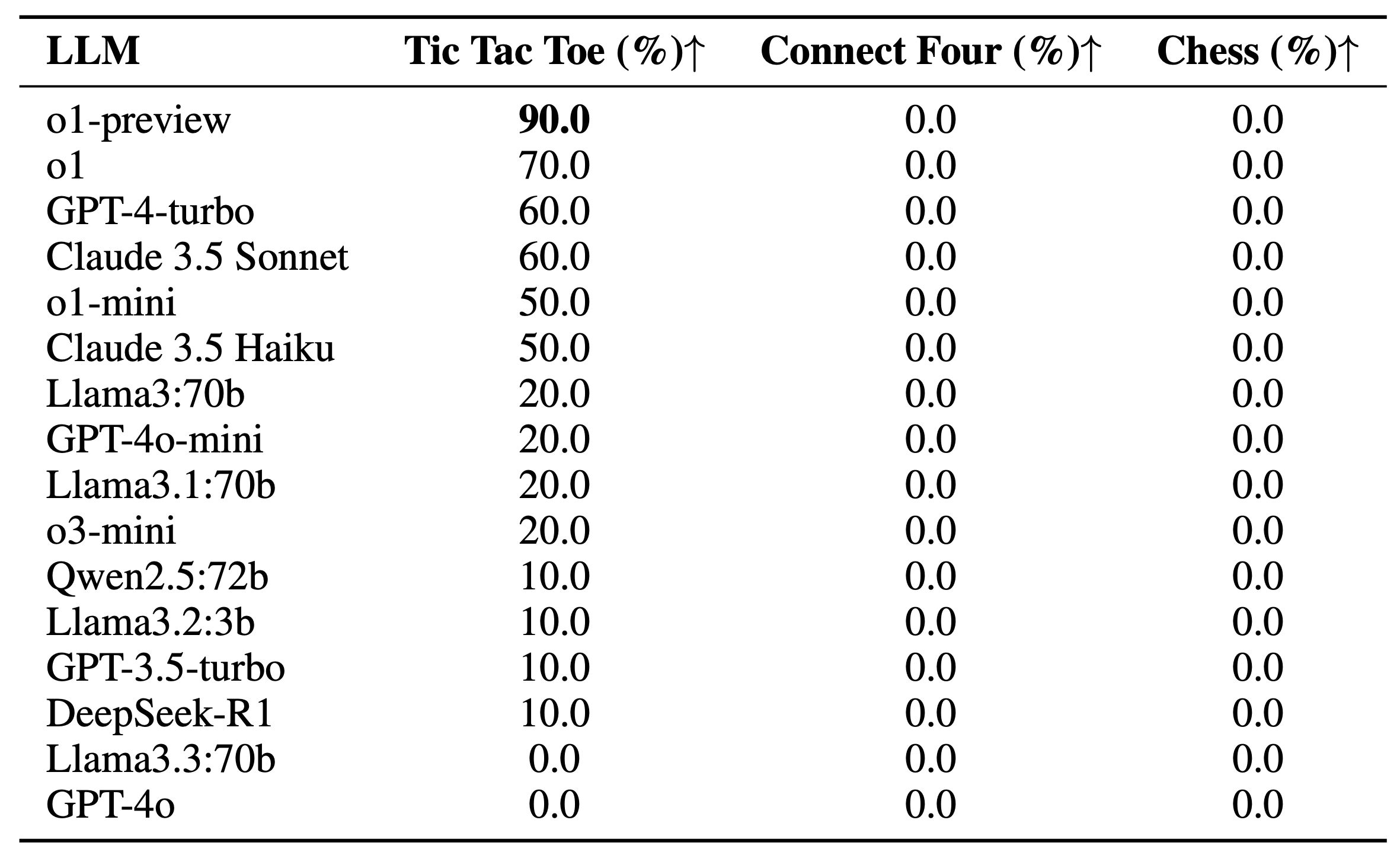
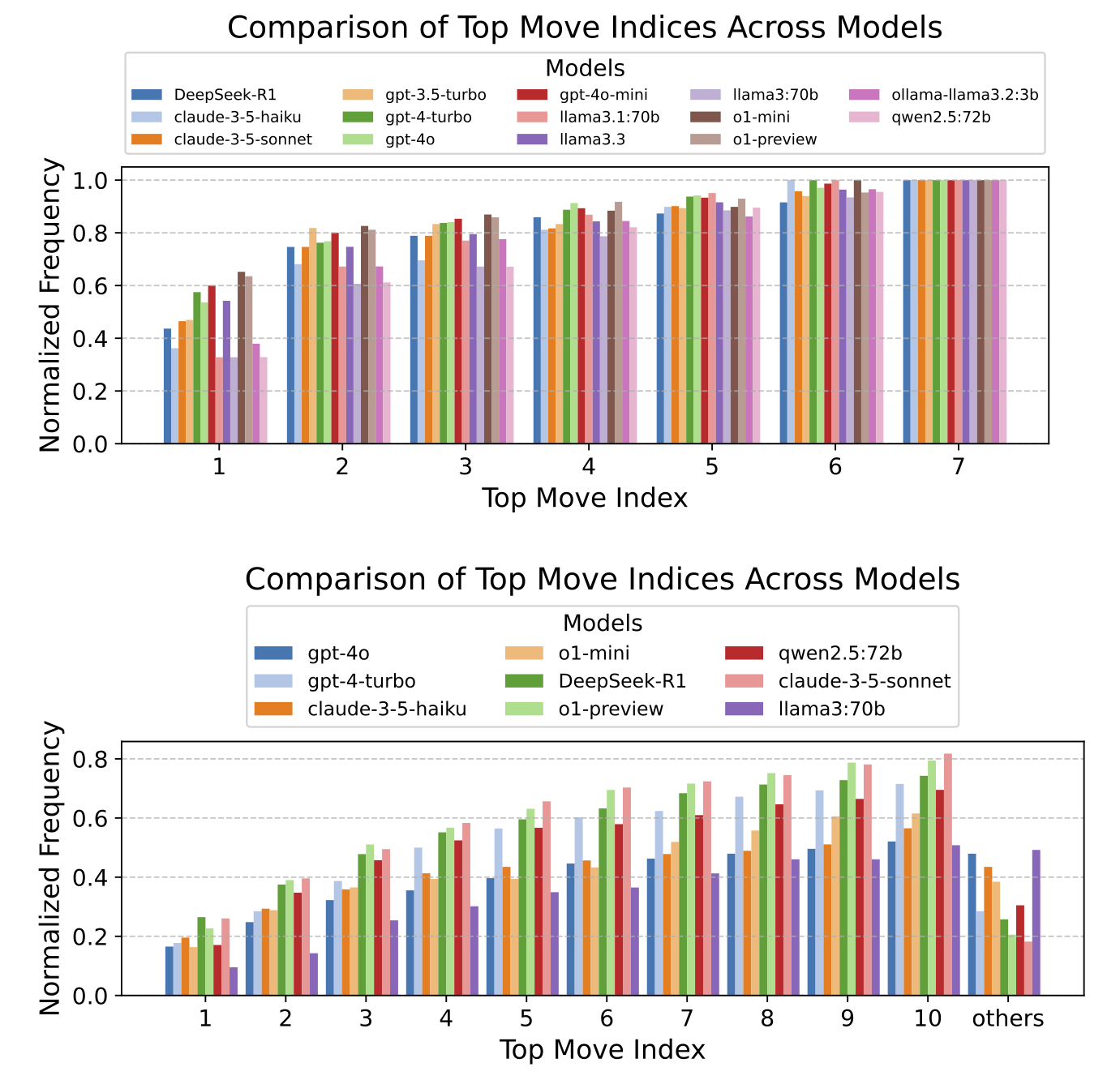
- Competitive Games: Turn-based board games of escalating complexity (Tic-tac-toe, Connect Four, Chess)
that test adversarial reasoning from short-range tactics to deeper strategic thinking.
- Cooperative Games: Featuring Hanabi, a card game where players see others' cards but not their own,
requiring trust-building, inference about hidden states, and coordinated actions.
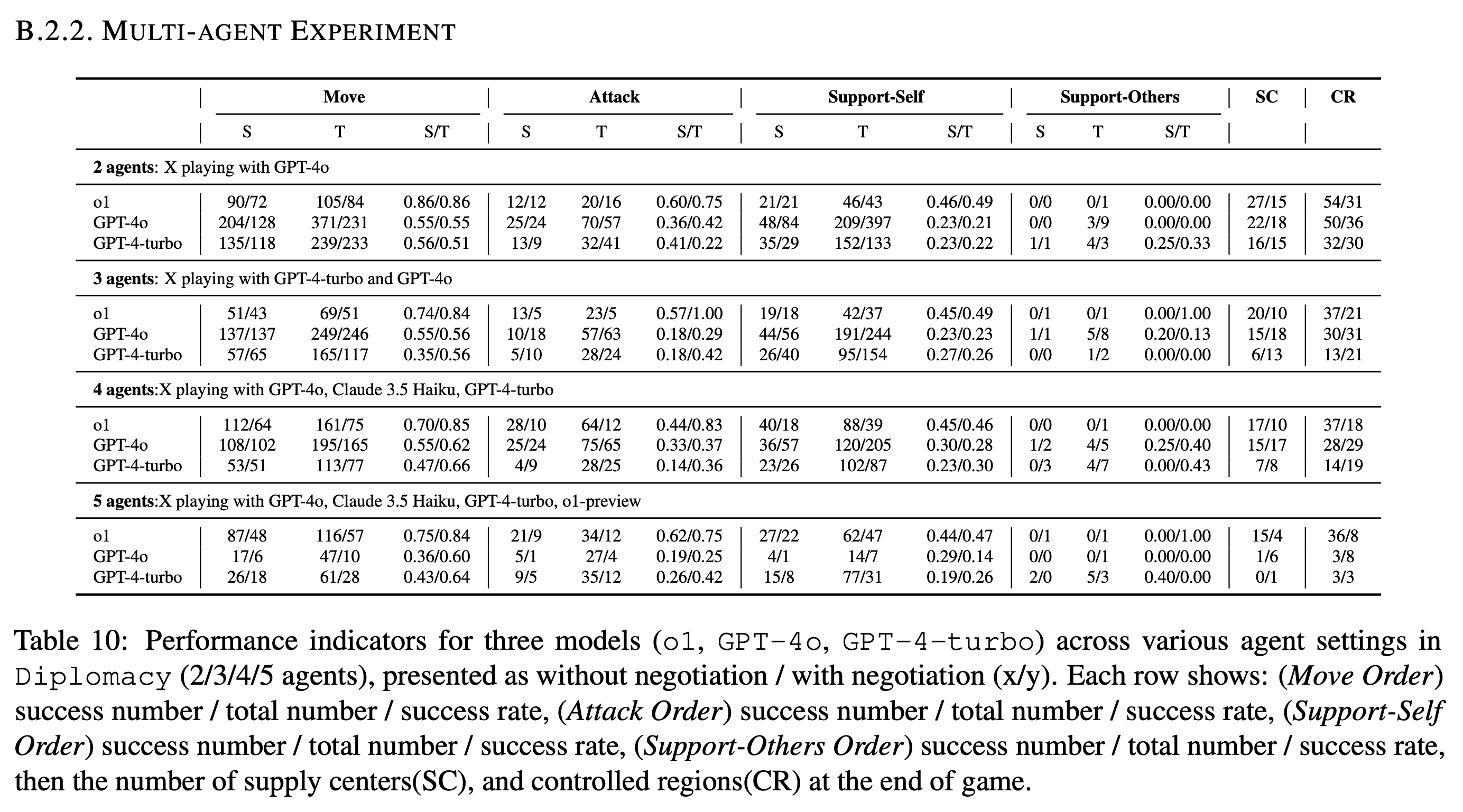
- Strategic Games: Incorporating Diplomacy, where negotiation, alliance formation, and strategic betrayal
are integral, testing both planning capabilities and social intelligence.
This structured progression allows us to systematically pinpoint where LLM reasoning breaks down—whether in state tracking,
partial-order reasoning, chain-of-thought coherence, or dynamic social interaction. By combining these environments
within a unified evaluation framework, SPIN-Bench provides unprecedented insight into how LLMs transition from
basic planning to complex multi-agent reasoning.